Introduction
Generative modelling aims to learn how data is produced, so a model can generate new, realistic samples rather than only classify or predict. Variational Autoencoders (VAEs) are a practical and widely used approach to generative modelling because they learn a probabilistic representation of data in a compact “latent space”. Unlike traditional autoencoders that compress inputs into a single point, VAEs learn a distribution over latent variables, making sampling and controlled generation possible. This makes VAEs valuable for tasks like synthetic data generation, anomaly detection, denoising, and representation learning, topics that often appear in modern machine learning curricula, including a data science course in Hyderabad.
What Makes a VAE Different From a Standard Autoencoder?
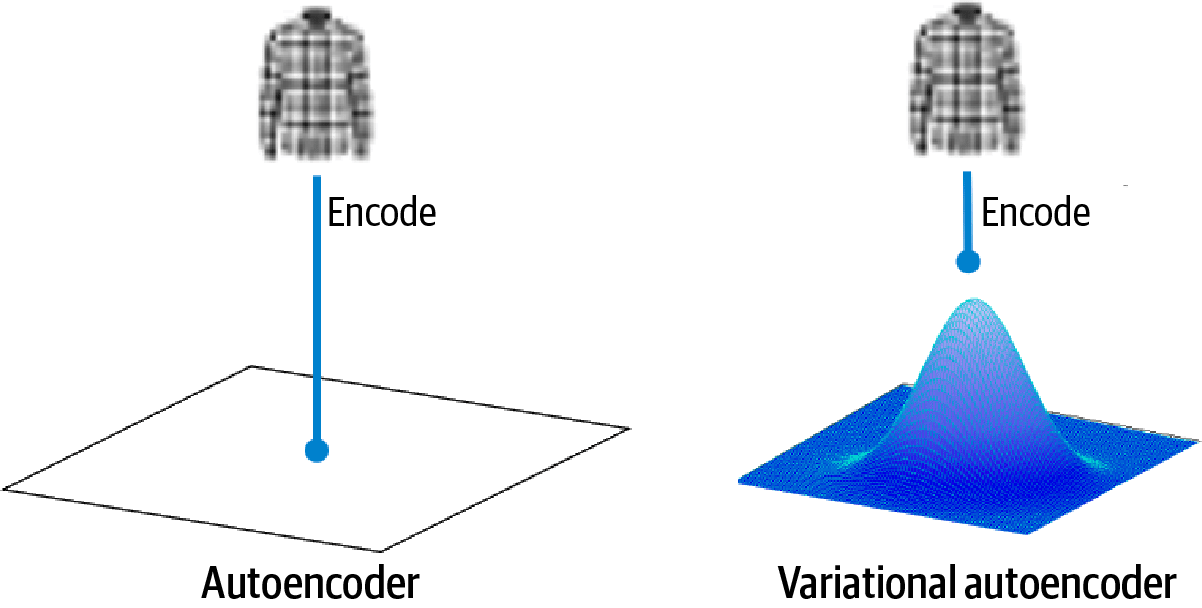
A standard autoencoder has two parts: an encoder that maps input xxx to a latent vector zzz, and a decoder that reconstructs x^\hat{x}x^ from zzz. It learns by minimising reconstruction error. The limitation is that the latent space can become irregular, nearby points may not decode to meaningful samples, and “random” latent vectors often produce nonsense outputs.
A VAE fixes this by making the latent space structured and continuous. Instead of outputting a single latent vector, the encoder outputs the parameters of a probability distribution, typically a Gaussian:
- Mean vector: μ(x)\mu(x)μ(x)
- Standard deviation (or log-variance): σ(x)\sigma(x)σ(x)
The model then samples zzz from q(z∣x)q(z|x)q(z∣x) and uses the decoder to reconstruct xxx. Because the latent variables are probabilistic and regularised, you can sample from the latent space to generate new data, or interpolate smoothly between data points.
The Core Objective: Reconstruction + Regularisation (ELBO)
Training a VAE is not just “reconstruct the input”. It balances two goals:
- Reconstruction quality
The decoder should reconstruct xxx accurately from sampled zzz. This is usually implemented as a negative log-likelihood (or a related reconstruction loss like binary cross-entropy for normalised images, or mean squared error for continuous features). - Latent space regularisation
The latent distribution q(z∣x)q(z|x)q(z∣x) is encouraged to stay close to a simple prior p(z)p(z)p(z), usually a standard normal N(0,I)N(0, I)N(0,I). This is done using the KL divergence term: - KL(q(z∣x) ∣∣ p(z))KL\big(q(z|x)\;||\;p(z)\big)KL(q(z∣x)∣∣p(z))
- This prevents the encoder from creating arbitrary, disconnected latent “islands”.
Together, this gives the Evidence Lower Bound (ELBO) objective:
- Minimise reconstruction loss
- Plus a KL penalty that keeps the latent space well-behaved
A practical note: this design is why VAEs may produce slightly “blurrier” samples than GANs in image tasks, because the model optimises a likelihood-style objective rather than an adversarial one.
The Reparameterisation Trick: Making Sampling Trainable
A key technical challenge is that sampling is not differentiable in the usual way. VAEs solve this with the reparameterisation trick:
Instead of sampling directly:
z∼N(μ,σ2)z \sim N(\mu, \sigma^2)z∼N(μ,σ2)
they sample:
ϵ∼N(0,I),z=μ+σ⊙ϵ\epsilon \sim N(0, I), \quad z = \mu + \sigma \odot \epsilonϵ∼N(0,I),z=μ+σ⊙ϵ
Now the randomness is isolated in ϵ\epsilonϵ, and μ\muμ and σ\sigmaσ remain differentiable, allowing gradient-based optimisation. This trick is central to why VAEs are feasible with standard deep learning toolkits.
Where VAEs Are Used in Real Systems
VAEs are not only for generating images. Their probabilistic latent space is useful whenever you want compressed representations with uncertainty.
1) Anomaly detection and quality monitoring
Train a VAE on “normal” data (e.g., sensor patterns, transaction behaviour, application logs). If a new sample reconstructs poorly (high reconstruction error) or yields unusual latent behaviour, it can be flagged as anomalous. This approach is common in manufacturing, fintech fraud monitoring, and infrastructure observability pipelines.
2) Data augmentation and synthetic samples
In situations where data is limited or sensitive, VAEs can help generate synthetic samples that resemble the original distribution. This is often discussed in the context of privacy-aware machine learning and can support experimentation when real data access is constrained, an important practical theme in a data science course in Hyderabad.
3) Representation learning for downstream tasks
The latent variables zzz can become strong features for classification or clustering, especially when labels are scarce. Variants like semi-supervised VAEs combine generative learning with predictive objectives.
4) Controlled generation and disentanglement
Extensions like β-VAE increase the weight of the KL term to encourage disentangled factors (e.g., separating “style” from “content”). This is useful for interpretability and controllable generation, although it can trade off reconstruction quality.
Implementation Tips and Common Pitfalls
- KL collapse: Sometimes the decoder becomes so strong that the encoder is ignored, pushing q(z∣x)q(z|x)q(z∣x) close to the prior and reducing information in zzz. Techniques like KL annealing (gradually increasing KL weight) can help.
- Choice of reconstruction loss matters: match it to the data type (binary, continuous, count-based, etc.).
- Latent dimension tuning: too small can underfit; too large can reduce meaningful structure unless regularisation is strong.
- Evaluation: don’t rely only on sample visuals; check reconstruction metrics, latent interpolations, and downstream task performance.
Conclusion
Variational Autoencoders offer a clean, principled way to learn generative models by combining reconstruction with probabilistic regularisation. Their structured latent space enables sampling, smooth interpolation, uncertainty-aware representations, and practical workflows like anomaly detection and synthetic data generation. While they have trade-offs, especially in sample sharpness compared with adversarial methods, their mathematical clarity and versatility make them a foundational topic in modern machine learning learning paths, including a data science course in Hyderabad.